
Environment
- YugabyteDB - 2.2
- YugabyteDB - 2.4.1 or lower
Issue
- The database nodes in the cluster have high CPU utilization when the cluster is idle and not performing any operations/activities.
- In some situations, due to the tablet count being higher than 10k per database node and a large number of open concurrent connections to the database, the tablet server process gets terminated by Out-of-Memory Killer.
Resolution
Drop unused tables
The first recommended solution is to drop unused tables, as each table will create tablets according to the sharding strategy in use, which is by default 8 shards per table. Review your data and determine if you can drop test tables that are not in use, or see if you can do a schema re-design to reduce the number of tables required.
Colocated tables or Tablegroups
If your workload supports it, using colocated tables may be a partial solution. Colocated tables will reside on the same tablets, so there is no additional tablet overhead. Small, relational tables are a good candidate for colocated tables. Consider your options regarding colocated tables and see if you can modify your schema to fit into this use case:
https://docs.yugabyte.com/latest/explore/colocated-tables/linux/
Reduce shards per TServer
This is recommended for tables you know will not contain a large amount of data. You can set the values on a global level using tserver flags, or on a per-table basis, as noted in our documentation:
https://docs.yugabyte.com/latest/reference/configuration/yb-tserver/#sharding-flags
Note - The value yb_num_shards_per_tserver and ysql_num_shards_per_tserver must match on all yb-master and yb-tserver configurations of a YugabyteDB cluster.
Reduce Tablet count per node to 10k or less
Increase nodes in the cluster
Additional nodes will allow the distribution of tablets, and therefore reduce the number of tablets on any one node. Double the nodes in the cluster will halve the number of tablets per node, which may be an effective solution where possible.
Tune heartbeat interval and Rocksdb Memstore to decrease the overhead of each individual tablet
If you are unable to reduce the number of tablets to an acceptable number using one of the methods above, it is possible to reduce the overhead of heartbeat operations and the memory usage of each tablet by adjusting the following settings. Please confirm these values with Yugabyte Support for your specific use case
raft_heartbeat_interval_ms=1500
leader_lease_duration_ms=7500
leader_failure_max_missed_heartbeat_periods=6
memstore_arena_size_kb=64
Note: leader_lease_duration_ms should be less than the value of (raft_heartbeat_interval_ms x leader_failure_max_missed_heartbeat_periods).
Re-sharding Data(Tablet Splitting) - BETA
High tablet count can be reduced by Splitting Tablets ahead of time or changing the value at runtime. Re-sharding of data can also to used to improve query performance. For example, range scans can be optimized by explicitly specifying split at values during table creation time. Splitting can also be useful when shard size grows due to increasing the volume of data resulting in an imbalance of tablets per node. We can use Manual or Automatic Tablet splitting to evenly balance the tablets/tablet leaders for the table across all the nodes. Tablets can be split using the following mechanisms.
- Presplitting tablets
- Manual tablet splitting
- Automatic tablet splitting
Refer to Tablet Splitting to read further.
Note: There are few limitations to tablet splitting which are actively being worked on and will be resolved in future releases. This feature is still in beta. Refer to Current Limitations to read further.
Updating configuration flags via the platform
The following section contains step-by-step instructions on how to edit flags via the Yugabyte platform.
- Log in to the Yugabyte DB admin console.
- Click Universes->select the universe you want to make a change->nodes.
- Click on the Actions drop-down located at the top right corner.
- Click on Edit Flags as shown below.
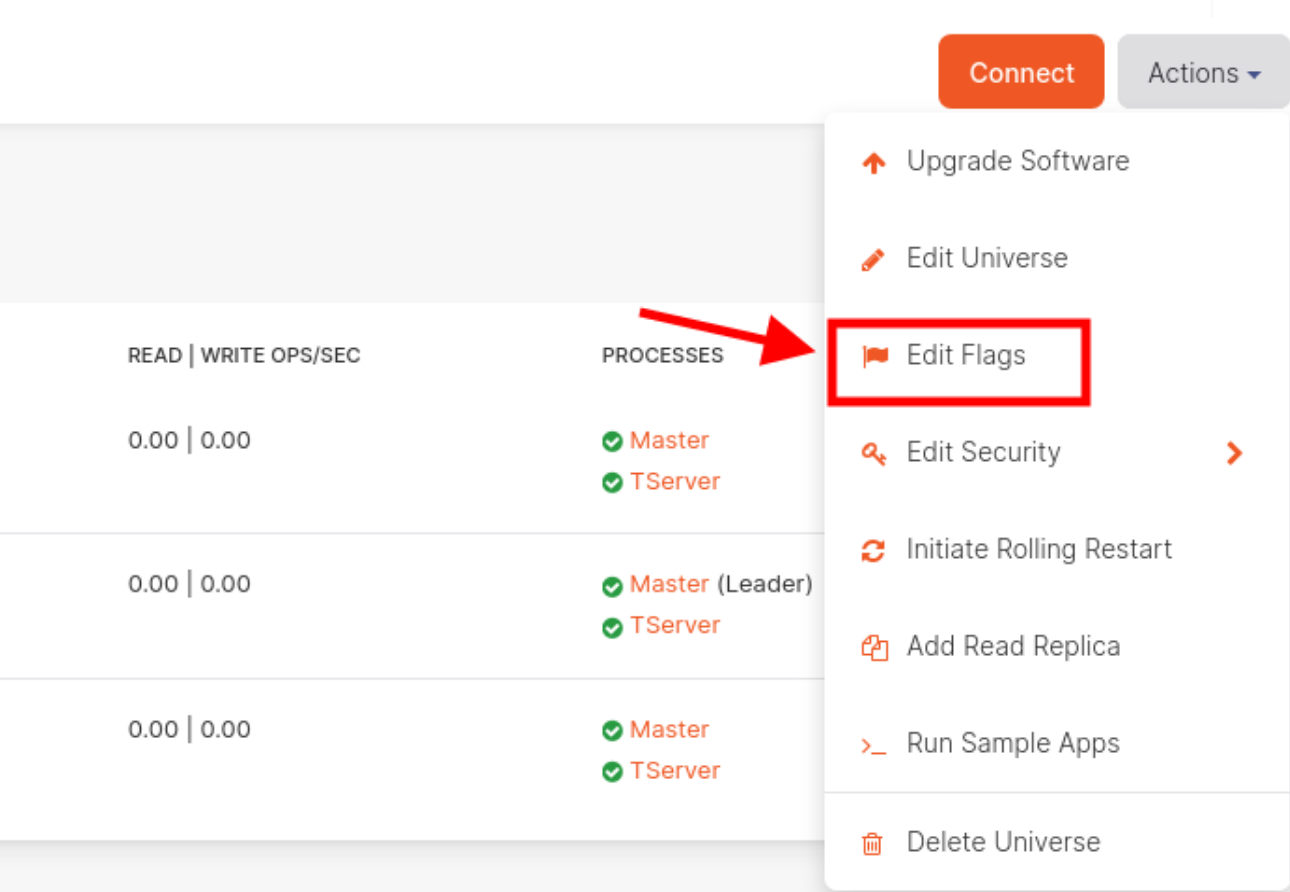
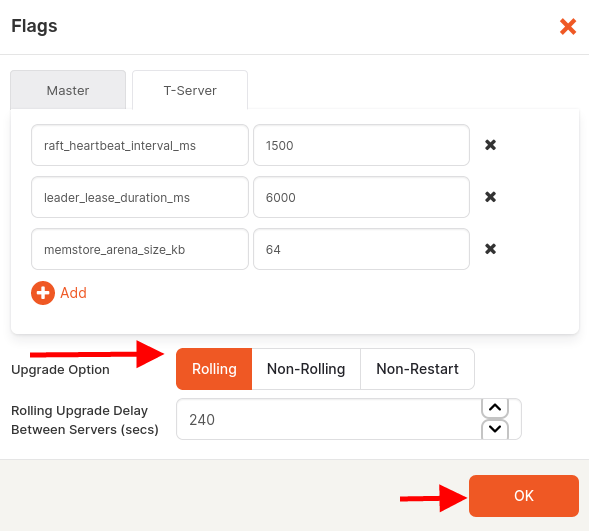
5. Update the values for both Master and T-server. Make sure Rolling is highlighted for the upgrade option and hit OK.
Overview
Yugabyte DB automatically splits tables into multiple shards, called tablets, using either hash or range-based strategy. Sharding is a process of breaking up large tables into smaller shards that are spread across multiple servers. A shard is essentially a horizontal data partition that contains a subset of the total data set. Since each table by default requires at least one tablet per node, a YugabyteDB cluster with 4000 relations (tables, indexes) will result in 4000 tablets per node. There are practical limitations to the number of tablets that YugabyteDB can handle per node since each tablet adds some CPU, disk, and network overhead. If most or all of the tables in the YugabyteDB cluster are small tables, then having separate tablets for each table unnecessarily adds pressure on the CPU, network, and disk.
One root cause is a high number of tablets causing load on the system due to heartbeats. Each tablet triggers a heartbeat according to the raft_heartbeat_interval_ms and a load of thousands of tablet heartbeats can be substantial.
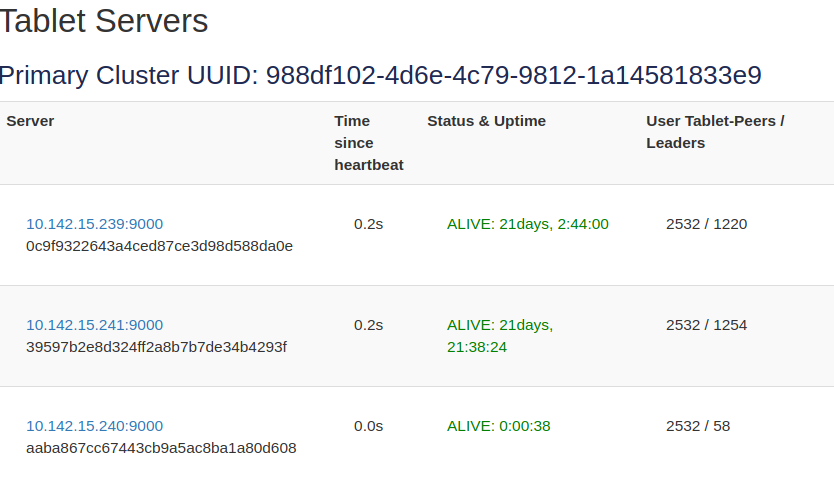
On the Master leader UI check for the number of tablets per node, noting the "User Tablet-Peers/ Leaders" - if this number is high, see the formula under the Diagnostic steps section to calculate expected CPU usage.
Diagnostic Steps
You can create a large number of tablets using the default settings of sharding( ysql_num_shards_per_tserver=8 default for node greater than 4 vCPUs) and simply create a large number of tables. At the default of 8 shards per ysql table, creating 500 tables will result in 4000 tablets. These 4000 tablets will be replicated according to the replication factor. If you are using 3 nodes and RF 3, you will have 4000 tablets per node. There is a rough formula to calculate CPU and memory usage of tablets. Using the default settings of heartbeat interval, every 100 tablets contributes to about 2.8% usage of a CPU in heartbeat operations.
CPU and Mem usage before and after tablets creation
for ip in ip1 ip2 ip3; do sudo ssh -i key.pem -p 22 centos@$ip "top -b -n 1 |grep -i 'cpu' |grep -v 'S'";done
for ip in ip1 ip2 ip3; do sudo ssh -i key.pem -p 22 centos@$ip "free -h";done
This could also invoke OOM killer. Check server diagnostic logs dmesg or /var/log/messages or /var/log/syslog based on your distro.
Out of memory: Kill process 23930 (yb-tserver) score 420 or sacrifice child
Killed process 24090 (postgres)
Memory usage by the subsystem
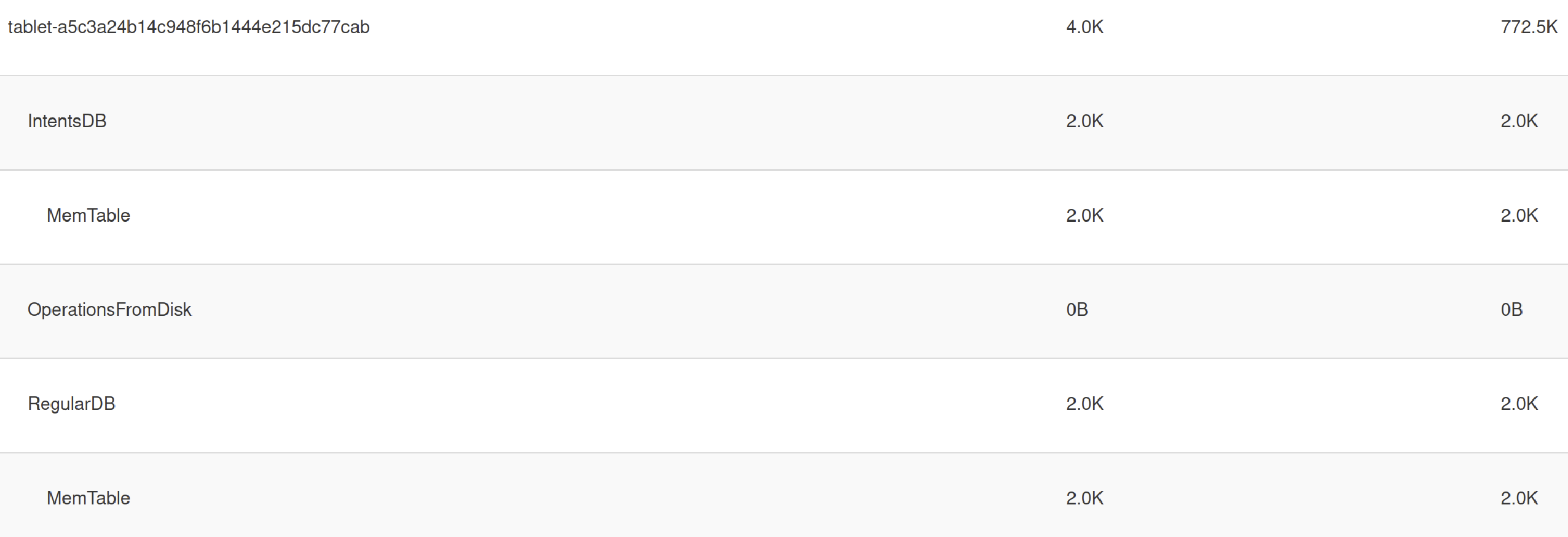
You can get current memory usage (Current Consumption, Peak Consumption, Limit) by running the below command. Convert HTML to Text and check memory consumed by a single tablet.
[yugabyte@yb-dev-yb-aa-scale-cluster-n1 ~]$curl -O http://`hostname`:9000/mem-trackers
[yugabyte@yb-dev-yb-aa-scale-cluster-n1 ~]$html2text mem-trackers >mem.txt
[yugabyte@yb-dev-yb-aa-scale-cluster-n1 ~]$ grep tablet-f486b44f2e854cbf84f3762474de6570 mem.txt
tablet-f486b44f2e854cbf84f3762474de6570| 4.0K| 4.0K| none
Memory breakdown is available at http://<server>:9000/mem-trackers
CPU usage = tablets/100 * 2.8%
Approx Memory usage = tablets * 4kb
So, for example, using the above 4000 tablets:
CPU usage = 4000/100 * 2.8% = 112%
That is, 4000 tablets should consume about 100%, or 1 total vCPUs, in processing time.
If you have any questions or feedback, please reach out to Yugabyte Support.
Comments
0 comments
Please sign in to leave a comment.