
Environment
This issue affects all currently released versions of Yugabyte.
Issue
- Soft memory limit errors
"Soft memory limit exceeded (at X% of capacity)" or "We have exceeded our soft
memory limit (current capacity is x%). However, there are no-ops currently
runnable which would free memory".
- Database operations fail with the message
"Operation failed, memory consumption has exceeded its limit or the limit
of an ancestral tracker". - Inbound RPCs are hung with the message
"Unable to allocate read buffer because of limit".
- Exceeding hard memory limits triggering OOM.
Resolution
Configure TServer flags to help alleviate the issue
This will require a restart of all the processes to take effect.
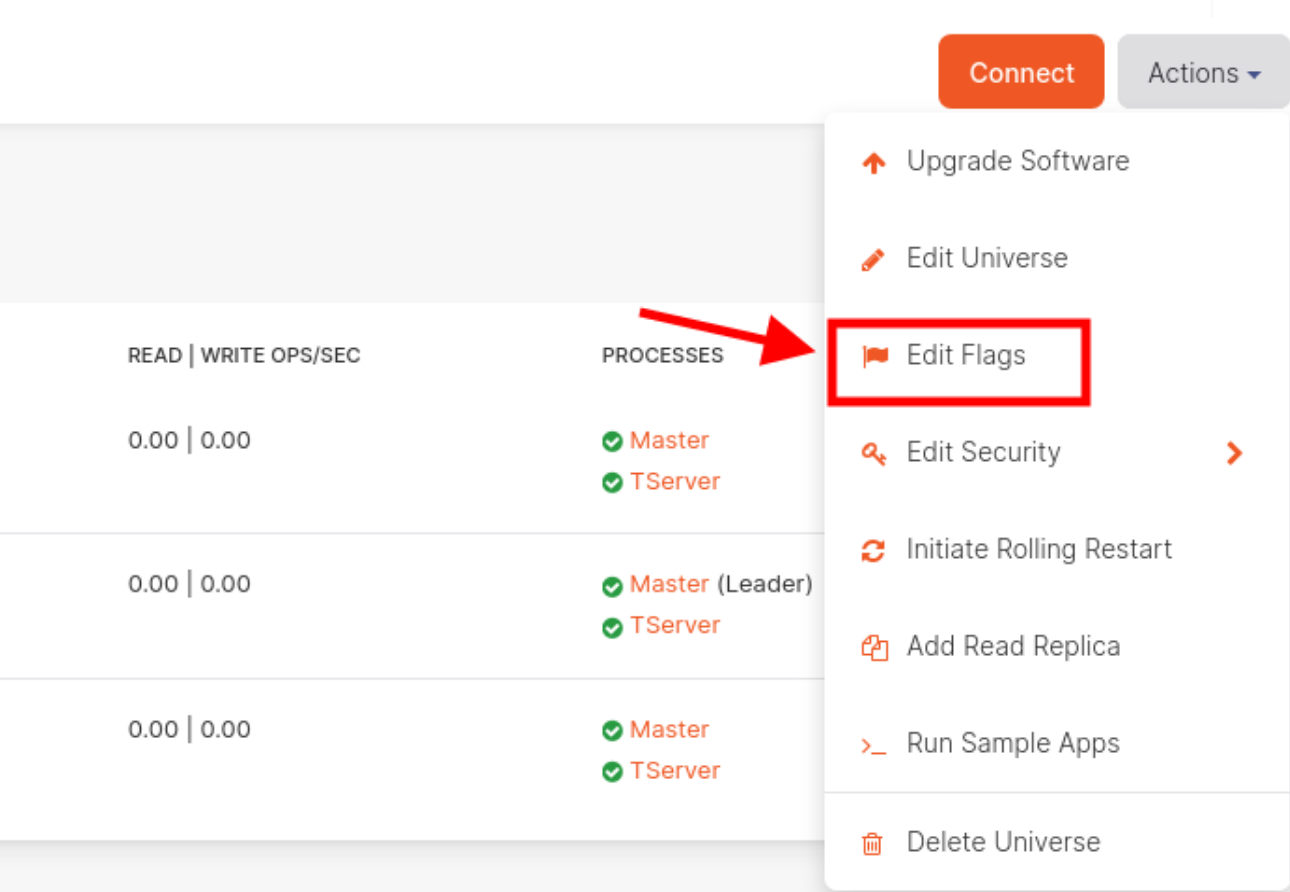
- Log in to the Yugabyte DB admin console.
- Click Universes > select the universe you want to make a change > nodes.
- Click on the Actions drop-down located at the top right corner.
- Click on Edit Flags as shown below.
db_block_cache_size_percentage = 40
global_memstore_size_mb_max = 1024
memstore_arena_size_kb=64
5. Update the values for T-server, check Rolling is highlighted for the upgrade option and hit OK.
The following section provides a description of each variable
src/yb/tserver/tablet_memory_manager.cc
...
67 DEFINE_int32(db_block_cache_size_percentage, kDbCacheSizeUseDefault,
68 "Default percentage of total available memory to use as block cache size, if not "
69 "asking for a raw number, through FLAGS_db_block_cache_size_bytes. "
70 "Defaults to -3 (use default percentage as defined by master or tserver).");
src/yb/tserver/tablet_memory_manager.cc
...
202 DEFINE_int64(global_memstore_size_mb_max, 2048,
203 "Global memstore size is determined as a percentage of the available "
204 "memory. However, this flag limits it in absolute size. Value of 0 "
205 "means no limit on the value obtained by the percentage. Default is 2048.");
src/yb/rocksdb/db/column_family.cc
...
52 DEFINE_int32(memstore_arena_size_kb, 128, "Size of each arena allocation for the memstore");
Reduce SQL Connections
Each SQL connection has some overhead, as there will be a separate postgres process per connection. Especially on systems with small amounts of memory, reducing the number of postgres connections may reduce the chances of OOM killing. This can be enforced by setting the ysql_max_connections flag:
https://docs.yugabyte.com/latest/reference/configuration/yb-tserver/#ysql-max-connections
Drop Unused Tables
The first recommended solution is to drop unused tables, as each table will create tablets according to the sharding strategy in use, which is by default 8 shards per table. Review your data and determine if you can drop test tables that are not in use, or see if you can do a schema re-design to reduce the number of tables required.
Reduce Shards per TServer or per Table
This is recommended for small tables. You can set the values on a global level using Tserver flags, or on a per-table basis, using a feature called Tablet Splitting. Refer to the following links for exploring both concepts.
Note - The value yb_num_shards_per_tserver and ysql_num_shards_per_tserver must match on all yb-master and yb-tserver configurations of a YugabyteDB cluster.
yugabyte=# create table t2(a int primary key, b varchar) split into 1 tablets;
CREATE TABLE
## The table has a single shard
./yb-admin -master_addresses ip1:7100,ip2:7100,ip3:7100 \
-certs_dir_name /home/yugabyte/yugabyte-tls-config list_tablets ysql.yugabyte t2
Tablet-UUID Range Leader-IP Leader-UUID
4a7815ac90e04b868bb7550ff134e517 partition_key_start: "" partition_key_end: "" 10.128.15.232:9100 41692e800d744a9cb095999b0c7aeafb
Colocated tables or Tablegroups - BETA
Another option to optimize for memory is to limit the tablets per node using a feature called Colocating Tables. This puts all of the data into a single tablet reducing the number of tablets per node, thereby reducing resource consumption and RPCs volume. If your workload supports it, using colocated tables may be a partial solution. Consider your options regarding colocated tables and see if you can modify your schema to fit into this use case.
Note: Colocation is enabled during database creation time. The data in the colocation tablet is still replicated based on the cluster replication factor. Refer to the following links for exploring more.
Note - This feature is in Beta and strictly should NOT be used in production environments.
yugabyte=# create database db1 with colocated=true;
CREATE DATABASE
yugabyte=# \c db1
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
You are now connected to database "db1" as user "yugabyte".
db1=# create table t3(a int primary key, b varchar) with (colocated=true);
CREATE TABLE
### Check both the tables belong to a single tablet
./yb-admin -master_addresses ip1:7100,ip2:7100,ip3:7100 \
-certs_dir_name /home/yugabyte/yugabyte-tls-config list_tablets ysql.db1 t3
Tablet-UUID Range Leader-IP Leader-UUID
1f642fd36b5b444591957af5425fac1d partition_key_start: "" partition_key_end: "" 10.128.15.231:9100 da9b674ba71f419fbd2fd8bb46a62470
./yb-admin -master_addresses ip1:7100,ip2:7100,ip3:7100 \
-certs_dir_name /home/yugabyte/yugabyte-tls-config list_tablets ysql.db1 t4
Tablet-UUID Range Leader-IP Leader-UUID
1f642fd36b5b444591957af5425fac1d partition_key_start: "" partition_key_end: "" 10.128.15.231:9100 da9b674ba71f419fbd2fd8bb46a62470
Root Cause
The following are some of the root causes:
- The database has a soft memory limit with a default value of 85% managed by the memory_limit_soft_percentage parameter which when exceeds, throttles the write request.
src/yb/util/mem_tracker.cc
...
75 DEFINE_int32(memory_limit_soft_percentage, 85, <----
76 "Percentage of the hard memory limit that this daemon may "
77 "consume before memory throttling of writes begins. The greater "
78 "the excess, the higher the chance of throttling. In general, a "
79 "lower soft limit leads to smoother write latencies but "
80 "decreased throughput, and vice versa for a higher soft limit.");
81 TAG_FLAG(memory_limit_soft_percentage, advanced);
-
In certain situations such as in the case of a large database operation and a node is restarted or a new node joins the cluster or when there is a huge lag between leader and followers, the RPCs size/calls for the data catchup between tablet leaders and followers significantly increases.
The tablet server is slow in processing these AppendEntries RPCs due to their volume. These inbound RPCs do not fit in the read buffer, binaryCallParser is unable to increase buffer size due to the memory limits, and requests indefinitely hang. Because of the exceeding memory limits, and TCP Receive buffer full, these request gets blocked from further processing. The unprocessed requests consume more memory reaching the hard memory limit and triggering Out of memory(OOM).
- This issue could also occur due to the high tablet count per node in the cluster. Please refer to the article High number of tablets.
- We have also seen the tablet server process crash due to an open issue with gperftools 2.8 package(tcmalloc library). please see the following GitHub issues for more details.
If you need more help, please reach out to Yugabyte Support.
Comments
0 comments
Please sign in to leave a comment.