
Environment
- Yugabyte core DB
- Database is running on a virtual stack, including Azure, HyperV, VSphere, Openstack
- This issue is not known to affect AWS or GCP, and should never affect bare metal installations
Issue
- Unexplained, seemingly random latency in query responses
- May see spikes in “Hybrid Clock Skew” metric
- Observe messages like
kernel: hrtimer: interrupt took 304726260 nsin the system log ordmesgoutput. This message in particular is indicative of the issue.
Resolution
- Engage with your hardware and virtual machine system administrators to identify which hypervisor settings are enabled
- Turn off hypervisor overcommitment
- Turn off snapshotting
- Turn off hypervisor migration. In VSphere, this is called “VMotion”. In Openstack, this is called “Live Migration”
- Ensure that NTP is enabled and running as noted in this article
- In general, YugabyteDB will continue to run, and the database is resilient to underlying instability, but query performance will be inconsistent until the underlying hypervisor issues are addressed.
Root Cause:
Underlying root cause
The primary cause of this issue is one where the hypervisor is configured in a way that may be disruptive to the guest virtual machine.
Any setting that may cause CPU starvation, virtual machine migration, or system pausing may result in the latency symptoms.
Hypervisor Overcommitment
In the case of an oversubscribed hypervisor, there are more CPUs allocated to virtual machines than there are physical cores available on the host. In this scenario, one or more noisy neighbors - guest systems that shares the same underlying hardware as the system running Yugabyte but are a different virtual machine - may starve CPU resources away from a Yugabyte node. This is the hardest scenario to detect, and would require insight from the admin team running your hypervisor to see settings related to CPU overcommitment.
You may be able to see if this situation is occurring by checking the %steal CPU metric, which is available in SAR data or prometheus.
From man sar:
%steal
Percentage of time spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was servicing another virtual processor.
An example prometheus query which graphs %steal:
avg(rate(node_cpu_seconds_total{mode=~"user|system|steal", node_prefix="<node-prefix>"}[56s])) by (mode) * 100In this scenario, the appearance to the database is that CPU processing would appear “slow”
As a rule, Yugabyte nodes should be given dedicated CPUs or assigned to their own dedicated physical resources. The largest impact will likely be unexplained latency.
Guest Migration
This may have different names depending on the hypervisor provider. In VSphere, it is called “VMotion” and in OpenStack, it is termed “Live Migration”.
In general, a migration of a guest means that the virtual machine is stunned, migrated to another host, and resumed. To execute this, the host must stop CPU execution of the guest for some amount of time.
Thus, all current operations, including Yugabyte queries, must also be paused.
This is an impactful operation, and thus is usually somewhat obvious from the guest. Logging, including both OS logging and any application logging, will generally appear absent for some seconds. Exported data, including prometheus data will be unavailable for the time window of the migration.
When the system resumes, it will generally have the same clock time it had when it was paused, but “real world” time will have advanced by however long the migration took. This may be noted in NTP or Crony logs.
The dmesg or system log (at /var/log/messages on Red Hat or Centos systems) will usually contain the message:
kernel: hrtimer took ###### ns
This message is documented in a Red Hat KB article here: https://access.redhat.com/solutions/194283
It is recommended to subscribe Yugabyte systems such that migrations are not permitted. You can disable VMotion for a single VM as described here and should consult with your vendor for other hypervisors.
YugabyteDB will survive a guest migration, but read and writes will have an latency of at least the migration time for some period after the actual event, as described below in “Cause of Database Latency”
Guest Snapshot
In this case, the guest is paused briefly for memory to be dumped. This may rarely be used to diagnose a hung system. An overview of snapshots in VSphere may be found here.. The symptoms are largely similar to those described in the Guest Migration section above, but often the total pause time is less. The impacts to the database are the same.
As noted in the above article:
Time-sensitive applications may be impacted by reverting to a previous snapshot. Reverting the snapshot will revert the virtual machine to the point in time when the snapshot was created. This includes any operations conducted by the time-sensitive service or application in the guest operating system.
Yugabyte is quite sensitive to time sync between the nodes of the cluster. Thus, While YugabyteDB will survive a snapshot, restoring the snapshot may cause data loss or corruption.
There is no value to snapshotting a node running Yugabyte as a backup and restore strategy, so they should explicitly be disabled.
Root cause of database latency
It is important to understand the behavior of hypervisor activities on the guest OS in order to understand the impact on YugabyteDB.
What happens in any of the above scenarios is that one node of the cluster, unknown to itself, becomes paused in a moment of time, while the rest of the world and the database continues on. Thus, at a minimum, it must catch up on work that was scheduled to it in the past and into “the future” that all of the other nodes have already completed.
This may be seen in some graphs of CPU across nodes that are affected - for example here, a group of machines that were snapshotted at 21:00 that have a few seconds of elevated CPU compared to before and tailing down, while they recover.
Prometheus query is:
avg by (exported_instance) (rate(node_cpu{node_prefix="node_prefix", job="node", mode="iowait"}[1m]))*100
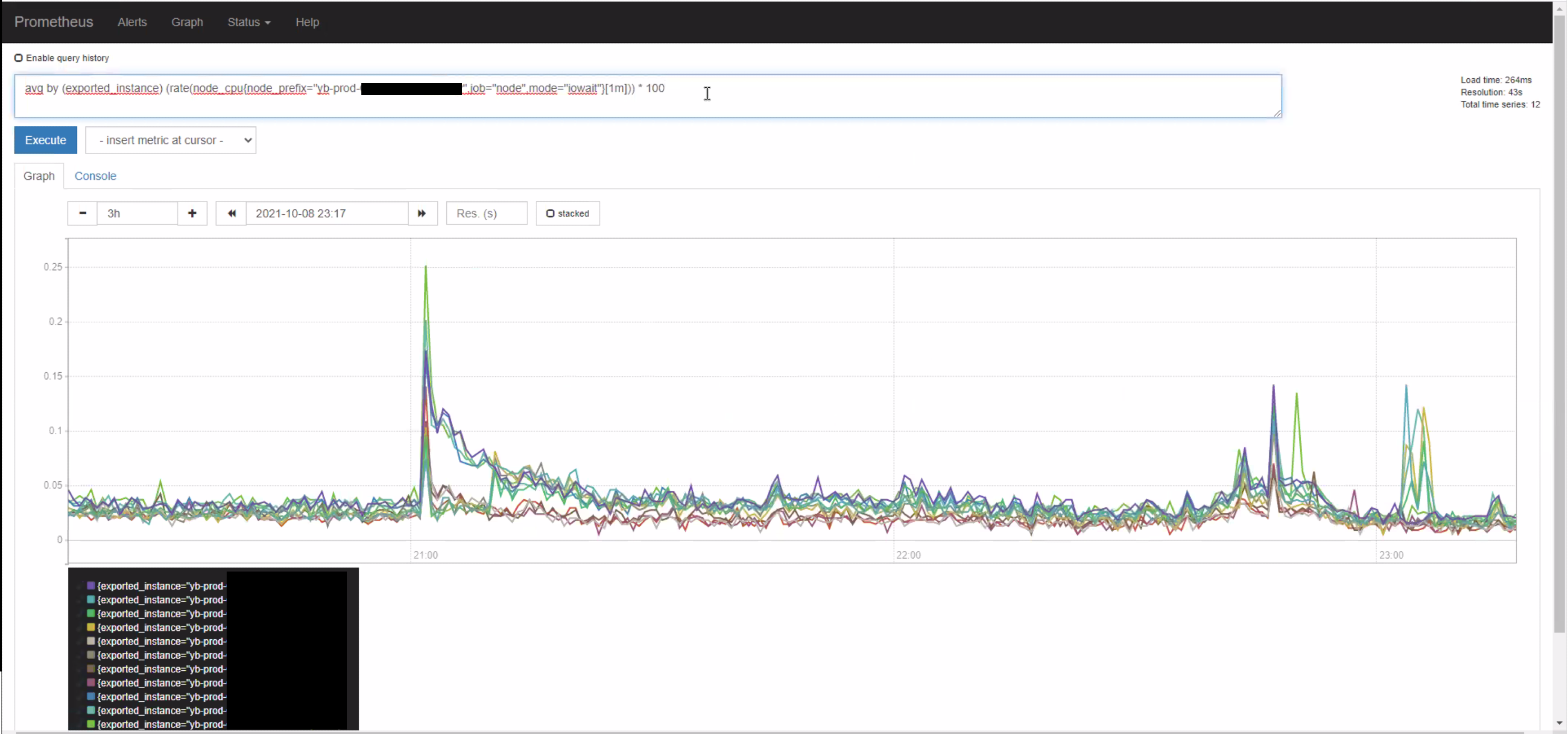
This situation gets worst in a couple of scenarios.
Guest pause of several milliseconds to a several seconds
In the case of extreme CPU contention, or a guest snapshot or migration, time stops from the perspective of the guest VM for a notable period of time, more than several milliseconds. Yugabyte’s Hybrid Logical Clock is now behind by some time on the node that was paused. As explained in the below article “Distributed Transactions without Atomic Clocks”, this means that reads, writes, and transactions must be delayed by at least the time difference between the nodes, to ensure database consistency.
This situation continues until NTP or Chrony catches up the time on the delayed node, which can take hours as time correction is applied gradually. Thus, the latency effects of an overcommited, migrated, or snapshotted server may be visible for a long time after the initial event.
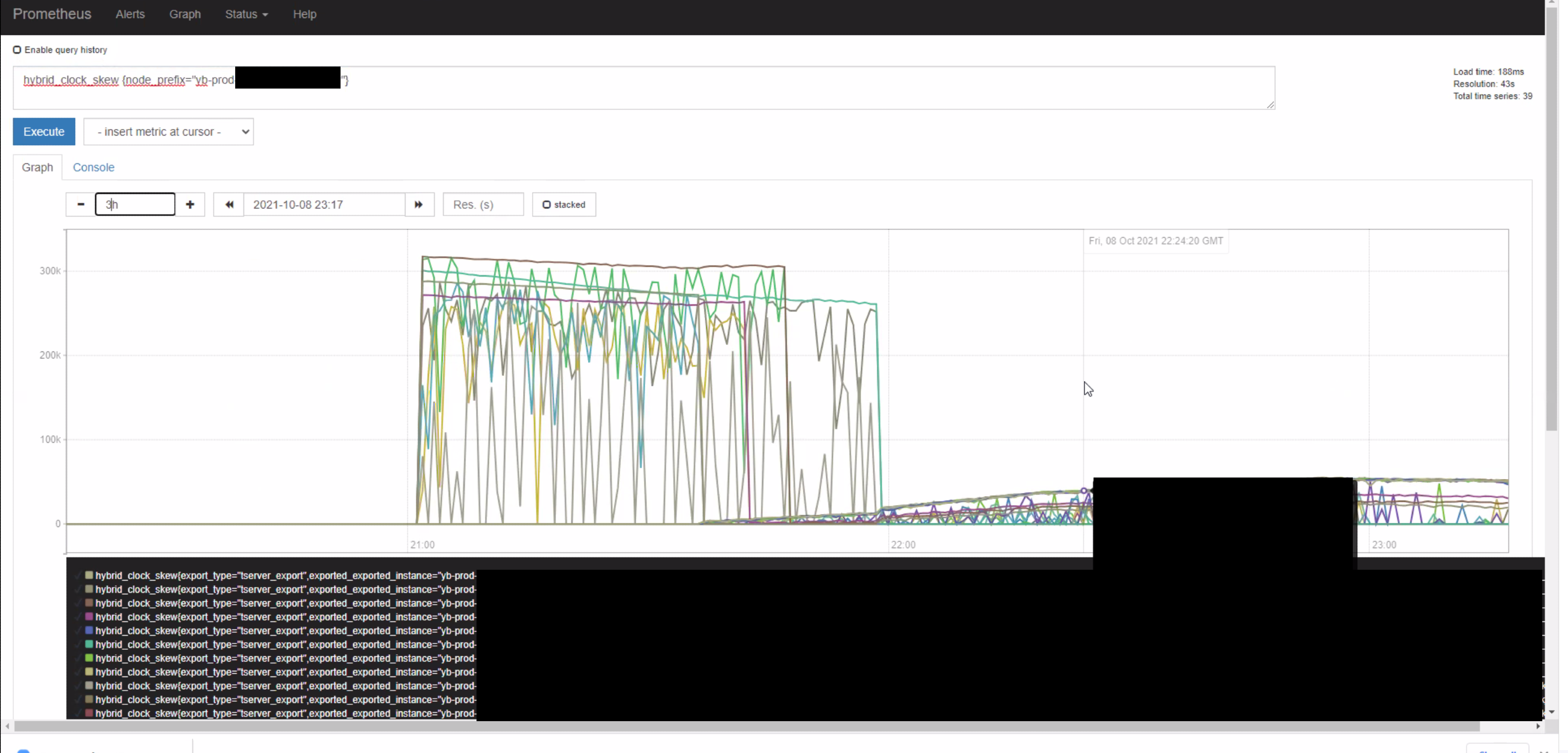
This behavior can be seen in the following graph of hybrid_clock_skew:
The prometheus query is:
hybrid_clock_skew {node_prefix="node_prefix"}
Consistent hypervisor overcommitment
In this scenario, a node is persistently competing for underlying hypervisor resources on a very busy system. The Yugabyte Node will frequently be starved of CPU resources, causing packet drops on the network, delayed acks, and general latency. Frequent leader elections may be noted on these nodes, which on their own cause latency.
When leaders are present on this node, they may intermittently and randomly be slow to respond - their CPU availability is dictated not by usage patterns on Yugabyte, but instead by noisy neighboring systems on the same hypervisor. This can lead to a maddeningly hard to diagnose systems of random high latency on the database side, that are not correlated to any other metric that would normally cause latency, like leader elections, high CPU utilization, NTP issues, or other workload on the system.
Additional documentation:
vSphere
vSphere vMotion
Understanding and troubleshooting vmotion
Overview of virtual machine snapshots in vSphere
# Setting the CPU limit of virtual machines may impact the ESXi utilization on overcommitted systems
OpenStack
Overcommitting CPU and RAM
Comments
0 comments
Please sign in to leave a comment.